
최근에 핫이슈였던 Sora와 Gemini 1.5에 발표에 맞추어서, 1-2년의 타임라인 기준에서 결국 AI 비즈니스에서 어떤 것이 경쟁력의 핵심이 될지에 대해 직접 써보았습니다. -하용호-
Update 2024/03/01 : 이 글은 3월 1일에 처음 작성하였습니다.
Update 2024/04/09 : 이 블로그의 내용 바탕에 최신내용을 추가하여 발표 자료로 만들었습니다. 4/6일에 션 앨리스와 함께한 그로스 컨퍼런스에서 강연을 하였습니다.

가장 발전한 OpenAI Sora로 기존의 것들이 퇴색되었습니다.
얼마전에 꽤나 소란스러웠던 시간이 있었습니다. OpenAI의 영상 합성 모델인 Sora가 발표되었기 때문입니다. 이제까지의 영상합성 모델과는 완전히 수준을 달리하는 결과물에 모두가 경악하였습니다. 기존의 비디오 합성은 누가 보더라도 꽤나 괴상하거나 합성임을 알아챌만한 퀄리티였지만, sora는 정말 달랐습니다. OpenAI는 정말 대단하네요.
.avif&blockId=66616d0b-4fa6-4636-894b-9aeaae990f3f)
그와 동시에 이제까지 이러한 영상을 만들어내는 생성형 AI 모델을 만들던 회사들은 허탈해지게 되었습니다. 바로 생각나는 건 Gen-2 모델을 만들던 Runway 이겠군요. ‘우리는 AI 비디오 생성의 최강자야’ 라는 자부심으로 지내왔던 Runway의 모델은 하루아침에 좀 구식의 무언가가 되어버렸습니다. Runway의 다음 투자 유치는 하루아침에 10배쯤 어려워졌겠군요
이런 파괴적 갱신은 모든 AI영역에서 매일매일 일어납니다.
이러한 일은 매일 일어나고 있습니다. 이번처럼 굵직한 소식은 크게 바이럴되며 뉴스가 되곤 하지만, 자잘한 모델들의 아웅다웅과 순위 격변 같은 것은 보이지 않은 곳에서 더 격렬하게 일어나고 있습니다. 공개된 대형언어모델(LLM)들의 성능 랭킹인 huggingface의 leaderboard 를 살펴보면 가요 랭킹 차트 보다도 더한 전쟁입니다. 오늘 누군가가 새로운 모델을 발표하고, 어제의 것은 구식이 됩니다.
.png&blockId=3b2f6d2e-757e-404c-a9e2-af26ff247b62)
위의 차트는 오픈되어 우리가 가져다 쓸 수 있는 언어 모델들의 성능이 시간에 따라 어떻게 좋아지고 있는가에 대한 것입니다. score 상단의 수평한 점선들은 인간의 능력을 점수로 표현 한 것입니다. 그리고 점차 오른쪽 위로 치닫고 있는 실선들은 오픈된 모델들이 얼마나 인간을 따라잡고 있는가를 보여줍니다. 점 하나하나는 각 회사들이나 개인이 최선을 다해 만들어낸 새로운 모델이고, 서로간의 경쟁을 거듭하며 인간의 능력에 수렴해가고 있습니다. 몇개월도 되지 않는 기간의 그래프에서 수십개의 새 모델이 업치락 뒤치락 하는 모습을 볼 때, 우리는 어떤 것을 깨달아야 할까요?
딥러닝의 3대 요소
마법과 같은 AI세상입니다. 이것이 어떻게 가능했는가에 대해서는 대체로 일관되게 3가지를 꼽곤 합니다.
1.
훌륭한 알고리즘
2.
고속 계산 하드웨어들
3.
대용량의 데이터들
이 3가지 축을 따라가며 고민을 함께 해나가 봅시다.
훌륭한 알고리즘
훌륭한 알고리즘이라면 대표적으로 지금의 LLM을 가능하게 했던 트랜스포머(Transformer)같은 알고리즘이나, 멋진 그림들을 그려내는 Stable Diffusion 같은 알고리즘들을 말합니다. 물론 공간쪽에서 쓰이는 NeRF같은 것들도 있구요. 여전히 많은 연구자들이 다양한 면에서 개선된 알고리즘을 내놓으며 피튀기게 싸우고 있습니다. 아까 위에서 본 모델들의 탑스코어 경쟁에서도 그러한 모습들을 볼 수 있죠. 다만 이 혁신의 속도를 바라보다보면 약간은 기가 질려서, 저 경쟁에 직접 뛰어들기보다는 ‘이기는 편 우리편’이라는 전략으로 승자를 기다리는 편이 훨씬 낫겠다는 생각이 들곤 합니다.
실제로 알고리즘의 우위는 영원하지 않습니다. GPT 3.5가 나왔을 당시의 첫 감상은 ‘이런 건 세상 누구도 못만들 것’같은 느낌이었습니다. 하지만 페이스북의 LLaMA 모델 공개는 전세계 연구자들의 가열찬 개조와 개발을 촉발 시켰고, 이제는 예전 GPT 3.5의 성능을 뛰어넘었다는 모델은 꽤나 자주 등장하고 있습니다. 물론 지금도 GPT 4의 성능은 최고입니다만, 그 턱밑까지 쫓아온 모델들이 상당합니다.
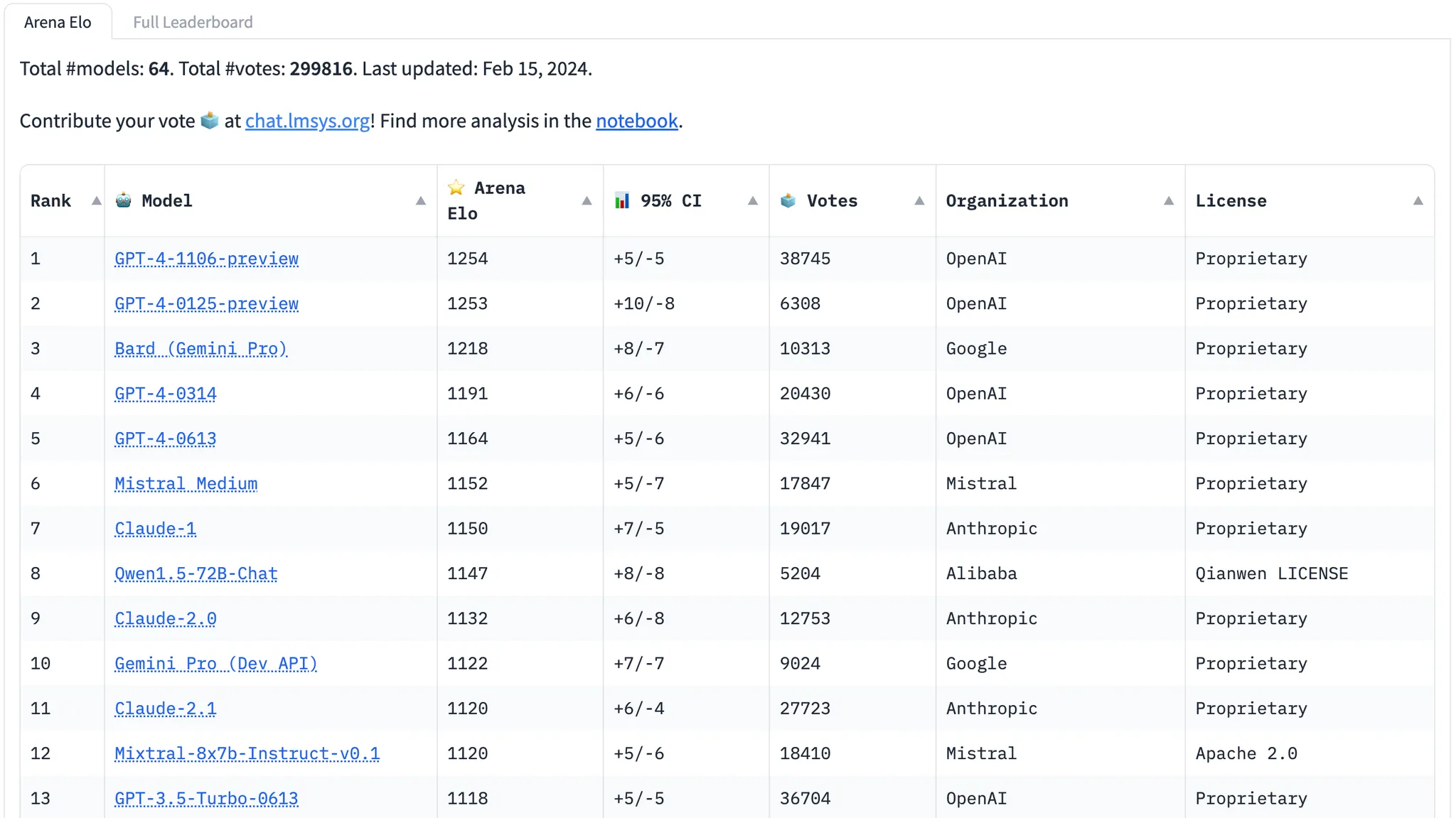
위는 https://chat.lmsys.org/ 에서 유저들의 체감 성능 투표에 의해 뽑힌 모델의 성능 순서입니다. GPT4와 3.5 사이에 여러 친구들이 포진해 있는 것을 볼 수 있습니다. 영원할 것 같은 GPT4의 성능도 언젠가는 다른 모두들이 수렴하지 않을까 싶습니다. 아직 한국어 기준에서는 쓸만한 오픈소스 모델이 드물기는 하지만, 이것도 시간이 해결해주지 않을까요? (새로운 국내 모델이 나오거나, 외국의 오픈된 모델이 한국어도 잘하게 되거나)
대단위 계산이 가능한 하드웨어
알고리즘이 수렴한다면 다음 경쟁 지점은 어디일까요? 하드웨어입니다. 다들 아시다시피 머신러닝의 학습에는 굉장히 많은 계산이 필요합니다. 계산을 빠르게 끝내기 위해서는 ‘순서(sequential)’대로 하는 것이 아니라, ‘병렬적(parallel)’으로 동시에 진행해야 합니다. 그리고 GPU는 이러한 병렬 계산에 특화된 프로세서입니다. 덕분에 이런 계산용 GPU를 만드는 NVIDIA의 주가는 하늘 높은 줄 모르고 솟아올랐고, 지금은 나스닥 전체 3위를 차지했네요. 세상에 주식 좀 더 사둘걸 ㅎㅎ
이제 AI회사의 경쟁력은 NVIDIA H100 기종 물량을 얼마나 확보할 수 있는가로 결정된다는 이야기가 있을 정도입니다. 돈주고도 못구하게 상황이거든요. 실제로 가장 많은 H100을 확보했던 메타와 MS의 주가가 가장 많이 오르기도 했으니 어느정도 맞는 말일지도 모르겠네요.
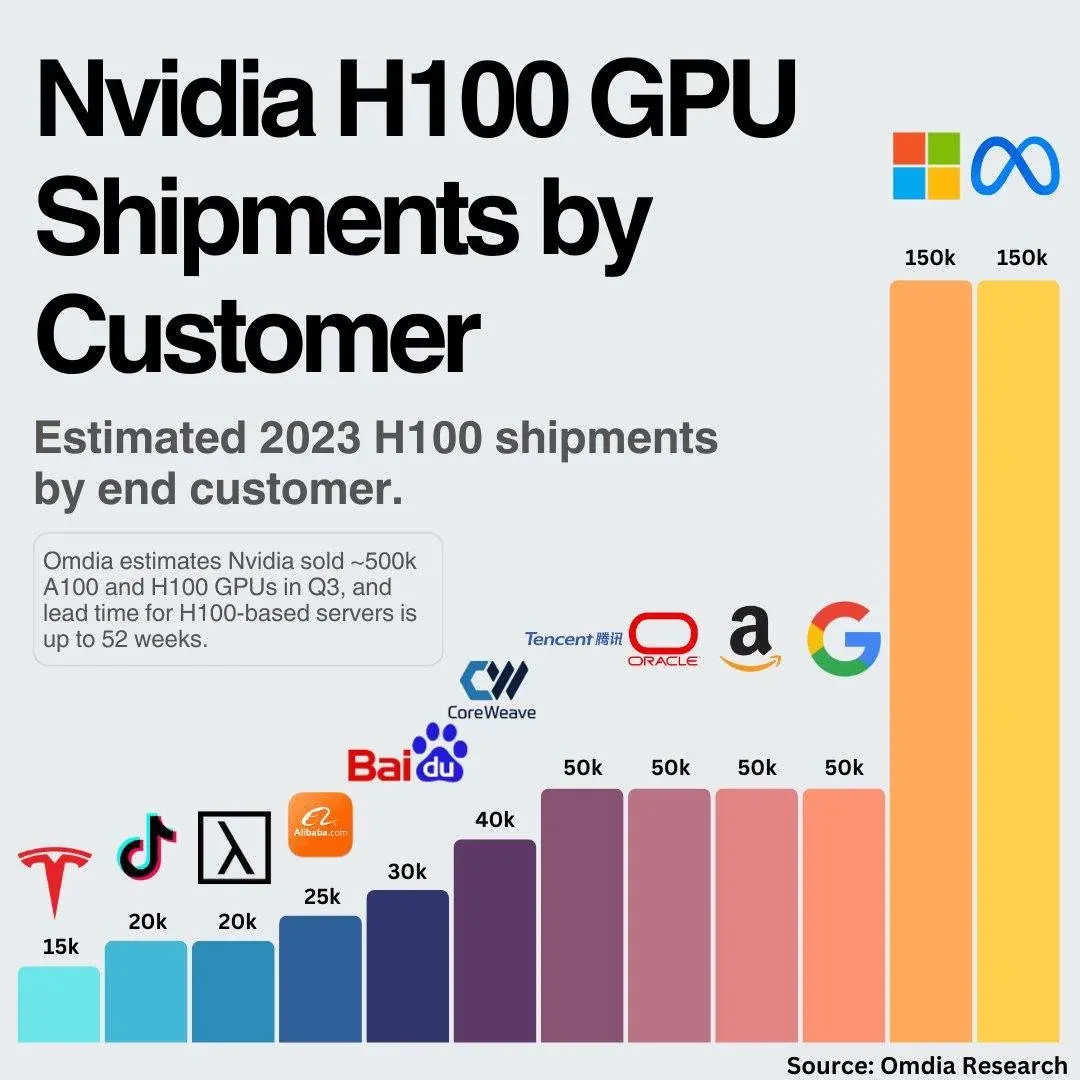
현재 각 회사의 AI경쟁력을 결정하는 것은 그걸 직접 개발하는 회사가 아니라, 하드웨어를 공급하는 NVIDIA가 되었습니다. 이렇게 하드웨어 공급사에게 발목잡혀 하고 싶은 것을 마음대로 할 수 없는 상황에 열받았는지, OpenAI의 샘알트먼은 9000조(!) 를 들여서 AI칩을 생산해 내는 새 생태계를 꾸릴 것이라는 엄청난 계획을 발표하기도 했죠. 머신러닝에서 하드웨어의 중요성을 다시 한번 느끼게 됩니다.
하지만 위와 같은 거대 중공업과 같은 흐름은 어찌보면 모델의 ‘생산자’관점입니다. 모델을 만드는 과정에서 ‘훈련(Training)’을 잘 하기 위해서는 매우 거대한 장비가 필요하지만, 훈련이 끝난 모델의 ‘소비자’가 되는 일반 기업들은 ‘추론(Inference)’이 잘 작동하기만 하면 됩니다. 이를 위한 여러 시도들이 활발하게 이루어지고 있습니다. 훈련된 ML모델을 더욱 작고 가볍게 만드면서도 성능을 유지하는 모델 경량화 기술들이 대거 등장하고 있으며, 이런 모델들을 작은 장치에서도 가볍게 돌릴 수 있게하는 많은 추론 전용 하드웨어들이 나오고 있습니다. 이 발전이 수렴하는 시점에서 ‘사용자’관점에서는 하드웨어 장벽도 크게 의미가 없어질 것입니다.
대용량의 데이터들
결국 마지막으로 남게 되는 것은 데이터들입니다. 데이터들은 크게 2가지로 나눌 수 있습니다. 누구든 웹으로 억세스 가능한 세상에 오픈된 데이터 (public data)와 개별 회사나 개인이 보유한 사적 데이터들(private data)입니다. 이제까지 우리가 신기해하던 GPT4나 Stable Diffusion 같은 머신러닝들은 대체로 이런 public data에 기반해서 만들어지고 있습니다. OpenAI의 GPT나 구글의 gemini등을 만들기 위해서 필요한 데이터의 양은 어마어마해서 보통 수십억개의 웹페이지, 공개된 논문들, 데이터베이스등이 사용됩니다.
반대로 말하자면 GPT등의 LLM등은 학습하는데 공개된 정보만을 사용하였기 때문에, 정말 똑똑하더라도 우리 회사 내부의 private한 정보는 아무것도 모릅니다. 때문에 정말 우리 회사 실무에 완전히 커스터마이즈되어서 동작하기 위해서는 이렇게 public data만 알고 있던 녀석들에게 private data를 반영시켜줘야 합니다.
private 데이터를 반영하기 ‘기술들’
LLM에게 private data를 반영시키는 대표적인 기술은 파인튠(finetune)과 RAG입니다. 파인튠은 기존의 LLM을 추가적으로 훈련을 더 시켜서 우리회사의 private한 정보들까지 알고있는 새 모델을 만드는 과정입니다. 비유를 들어보자면 LLM은 세계 최고의 학교에서 공부도 열심히 하고 다방면의 지식을 가진 매우 훌륭하고 똑똑한 인재이지만, 우리 회사에 대해서는 아무것도 모르는 친구라고 생각하면 됩니다. 이 친구에게 우리 회사 일을 맡기기 위해 회사 연수원에서 몇달 굴려서 새 인간(?)으로 거듭나게 하는거죠. 연수원에서 개조(?)되어 나온 이 친구는 이제 우리 회사일을 잘 해낼 수 있을 겁니다.
다만 파인튠은 어쨌거나 새 모델을 만드는 과정입니다. LLM이라는게 원래도 다루기 힘든 거대 모델이다보니 조금 만 더 업데이트 시키는 과정이라 하더라도 일이 좀 큽니다. 요즘은 LoRA등의 좀 더 가볍게 업데이트하는 여러 기법이 나오기는 했지만 여전히 꽤 좋은 하드웨어와 비용과 시행착오가 필요합니다. 때문에 많은 회사들은 파인튠에 집중하기 보다는 조금 더 간편한 RAG로 접근하고 있습니다.
RAG는 Retrieval-Augmented Generation의 약자입니다. 순서대로 번역해보면 ‘검색(Retrieval)→증강(Augmented)→생성(Generation)’ 입니다. LLM에게 일을 시키기 전에, 지금 시키려고 하는 일과 가장 관련성이 높은 우리 회사의 내부 데이터를 찾아 (검색), 프롬프트를 만들 때 이 지식들을 덧대어 LLM에게 지식을 알려주면서(증강), 궁금한 것을 물어 답을 얻습니다(생성).
비유해보자면, 훌륭하지만 우리 업무는 모르는 알바를 뽑았을 때, 이 친구에게 일을 시키면서, 업무 메뉴얼에서 도움이 될만한 페이지를 발췌해서 복사해주고 ‘참고하면서 일해’라고 하는 것과 비슷합니다.
그런데 왜 이렇게 번거로운 절차를 걸쳐서 하고 있을까요? 한번에 필요한 정보를 다 주면되지, 굳이 검색이라는 과정을 통해서 일부분씩만 전달해줄까요? 그건 LLM이 한번에 기억하고 처리할 수 있는 양에 제한이 있기 때문입니다.
LLM은 컨텍스트 윈도우(Context Window)라고 부르는 사이즈만큼 기억하고 묻고 대답할 수 있습니다. 이 컨텍스트 윈도우의 크기는 처음 GPT가 나왔을 때 4096 토큰 사이즈 였으며, 가장 최신의 그리고 가장 비싼 GPT4가 128k의 사이즈를 가집니다. (정의상 1 토큰은 여러글자일수도 있지만, 한글 기준에서는 편의상 1토큰이 1글자라고 생각해도 무방합니다.) 저건 아직 작은 사이즈여서, 가장 비싼 모델을 써도 한 회사의 전체 데이터를 담기에는 턱없이 모자란 양이죠.
때문에 검색이라는 과정을 통해 작은 사이즈로 발췌를 해야 하는 이유가 생기고, 여기에 많은 테크닉이 들어가게 됩니다. LangChain이라던가 LamaIndex라던가 하는 많은 라이브러리들이 이 문제를 풀기 위해 나왔고, 많은 스타트업들은 이것들을 이용해 새로운 서비스들을 출시하고 있습니다. ‘우리 회사는 훌륭한 AI기술을 가지고 있다’라고 말하는데, 알고보면 ‘남들보다 RAG를 잘 써서, 작은 컨텍스트 윈도우를 잘 활용할 줄 안다’ 인 경우가 꽤나 많습니다. 그런데, 과연 이 RAG 테크닉으로 AI 우위를 잡는게 앞으로도 의미가 있을까요?

Sora에 묻혔지만 사실 중요했던 뉴스
OpenAI의 Sora가 워낙 큰 주목을 받았기에 상대적으로 묻혀버렸지만 저 개인적으로는 Sora보다도 더 중요하게 느껴지는 발표를 구글이 하였습니다. 바로 Gemini 1.5의 발표입니다. (Gemini 소식은 여러모로 국내에서는 소외되고 있는 느낌이긴 합니다) Gemini 1.5는 컨텍스트 윈도우 사이즈와 관련해 큰 돌파구를 보였습니다. 바로 100만개 사이즈의 컨텍스트 윈도우를 가지고 있다고 발표한 것입니다.

100만개의 컨텍스트 윈도우는 그야말로 아주 방대한 양입니다. 몇백페이지 짜리 왠만한 책은 통째로 들어가는 사이즈입니다. 소규모회사라면, 전체 지식을 통째로 넣을 수 있는 사이즈입니다. (우리 회사의 사내 인트라넷 Wiki나 Notion의 지식부분만을 텍스트들로 추출한다고 생각해보세요. 생각보다 얼마 안될겁니다)
애초에 RAG는 부족한 컨텍스트 윈도우에 우리 회사의 데이터를 요리조리 잘 잘라넣어보려는 테크닉이었습니다. 컨텍스트 윈도우 자체가 이렇게 엄청나게 커진다면 그 기술의 중요성은 퇴색하겠죠. 그리고 앞으로 나올 모델들은 분명 더 크게 나오거나 우회해 극복하는 기술을 품은 채 나오게 될겁니다. 그리고 이렇게 극복하는 기술을 LLM 자체가 품어갈 수록, 개별 회사가 가지는 RAG 테크닉의 중요성은 점차 줄어들 것입니다.
모든 것이 의미없어질 때 유일하게 남는 것은?
이상의 과정을 위해 머신러닝의 핵심요소들이 어떻게 점차 의미를 잃어가는지 살펴보았습니다. 훌륭한 알고리즘은 결국 모두가 다 일정 이상 성능의 모델을 쓰게 됨으로써 경쟁우위가 없어집니다. 훌륭한 하드웨어는 모델 경량화 기술과 서비스용 저렴한 추론 하드웨어 발전으로 경쟁 우위가 없어집니다. 이제까지 꽤 중요한 경쟁력이었던 데이터를 잘 핸들링 하는 테크닉은 핸들링이 필요없는 아주 큰 컨텍스트 윈도우를 가진 모델들의 등장으로 경쟁우위가 없어지게 됩니다.
데이터에서 테크닉 부분이 사라지고 나면, 결국 남는 것은 private data 그 자체 밖에 없다고 생각합니다. 저는 이것을 쥐는 회사가 결국 이 AI 전쟁에서 최종적으로 승리할 것이라고 생각합니다. 나머지들은 남들이 확보가능하지만, 우리 회사와 우리 서비스만이 가지고 있는 독보적인 private 데이터 - 즉 남들은 돈을 주고도 구할 수 없는 closed dataset - 만이 개별 회사의 경쟁력으로 수렴해 나갈 것이라고 생각됩니다.
그런 의미에서 뜻밖의 승리를 쥘 것이라 생각하는 두 회사
지금의 AI 전쟁에서 가장 선두를 차지하고 있는 회사는 ‘훌륭한 알고리즘’을 구현한 OpenAI와, ‘훌륭한 하드웨어’를 만들어내고 있는 Nvidia입니다. 하지만 저는 결국에는 Google과 Apple이 다시 치고 올라올 것이라고 생각이 됩니다.
private data의 최고봉은 personal data 일것입니다. 세상에서 가장 많은 personal data를 확보한 회사는 구글입니다. 내가 지난 몇년동안 해왔던 검색기록, 크롬을 통해 쌓아온 웹페이지 방문 기록, 지메일을 통해 어떤 메일을 주고 받는지, 유튜브를 통해서 내가 어떤 컨텐츠를 보고 울고 웃고, 또는 공부하고 노는지를 알고 있는 곳이 구글이기 때문입니다. 개별 개인에 대해 가장 집약된 데이터를 ‘직접’ 보관하고 있는 구글은 결국 장래에 평준화된 알고리즘과 하드웨어 위에서 제 데이터를 가장 크게 레버리지할 것이라고 보입니다.
그런 의미에서 애플도 한방이 남아있다고 생각합니다. 애플은 기조상 데이터를 직접 보관하고 있지 않지만, 내 모든 데이터가 지나다니는 통로인 스마트폰을 쥐고 있습니다. 정보의 유통경로를 쥐고 있는거죠. 제 동의만 얻는다면 가장 가까이서 모든 personal data를 억세스할 수 있는 곳이 애플입니다. 휴대폰 위에서도 가볍게 돌아가는 LLM이 대중화되는 시점에서 LLM과 통합된 iOS가 나 대신 직접 앱을 실행하고, 배민에서 리뷰를 읽고, 내 취향을 반영해서 메뉴를 골라주고, 대신 결제까지 완료해줄지도 모릅니다. 아니 분명히 그러겠죠.
그렇다면 일반 회사들은 AI 비즈니스를 어떻게 접근해야하나?
최근에 회사들을 보면 ‘우리도 GPT를 쓴다. 우리도 AI를 써서 서비스 만든다.’ 같은 타이틀에 집중하는 케이스가 종종 보입니다. 당장은 개별 기술 요소가 중요해보일 수 있지만 미래의 큰 방향을 생각해본다면 우리 회사는 ‘어떻게 해야 독립적이고 배타적인 private data를 획득할 채널을 만들것인가’ 가 가장 중요한 질문이 될 것이라 생각합니다. 우리 비즈니스의 어딘가에서 구글 같은 정보의 수집자가 될지, 애플같은 정보의 유통채널 독점자가 될지 잘 찾아봐야겠습니다. 배타적인 private data는 우리 회사가 기존에 이미 잘 하고 있는 본질 비즈니스 주변에서 발굴됩니다. 우리 유저와 우리 비즈니스를 살펴보세요. 우리 회사만 가질 수 있는 데이터(private data)가 무엇이 될지 생각하세요.
P.S. 저는 그래서 최근에 애플과 구글 주식을 샀습니다. 아마 단기적으로는 좀 더 NVIDIA와 마소보다 빌빌댈 것이라 생각하지만, 길게본다면!!
P.S.2 이 글은 AI를 비즈니스에 접목하려는 일반 회사들을 대상으로 쓴 글입니다. AI기술 자체를 목적으로 하는 테크 회사에게는 여전히 모든 축이 유의미합니다. 테크회사들이 잘 만들어주셔야 다른 회사들이 데이터에 집중할 수 있습니다 